Dataset Condensation整合版
目录
- Data Pruning via Moving-one-Sample-out
- D² PRUNING: Message Passing for Balancing Diversity & Difficulty
- Sieve: Multimodal Dataset Pruning Using Image Captioning Models
Data Pruning via Moving-one-Sample-out
这个是NeurIPS 2023的文章 Arxiv地址:https://arxiv.org/abs/2310.14664
背景与贡献
现有方法概述
Dataset Pruning的主流方法有:
- 重要性指标打分:entropy, SSP, Forgetting, GraNd/EL2N, Memorization 等
- 基于几何覆盖/样本多样性思想:Moderat, Herding, Coverage-centric, CCS等
- 优化方法:CRAIG, Grad-match, bi-level, submodularity等
研究动机
这篇文章引入名为MoSo的动态指标,将样本的loss梯度和数据集的平均loss梯度结合,作为评判依据,其目的为解决以下两个问题:
- 在重要性指标打分中,噪声和Hard Sample(较难识别出目标,比如label为黑天鹅但图中黑白天鹅都有的图片)往往很难区分。他们都会导致较高的loss,因而文章认为这些Hard Sample不一定十分重要。
- 训练动态很少被用于dataset pruning。主流方法往往对临近训练结束时对训练产生较好效果的样本,但忽略了对训练前期有作用的样本。这一原因是主流方法往往使用已经经过训练并达到收敛状态的代理模型。
主要贡献
- "MoSo utilizes the change of the optimal empirical risk when removing a specific sample from the training set to measure sample importance instead of only focusing on sample difficulty" 即不仅关注重要性,还关注某一样本对训练过程的影响。
- 关注了样本在不同训练阶段的对训练的影响。
MoSo的定义与实现
原始定义
对于一个样本z,其Moso指标的定义为在以去除样本z的数据集S/z上,数据集S/z上训练得到的最优模型参数与完整数据集得到的最优模型参数的平均交叉熵损失之差。
这个公式考量的是一个样本在删除前后对整体数据集loss的影响。如果删除z后,导致平均loss变小,那么可以说明它是相对有问题的数据,比如噪声,因此在M(z) < 0时,可以说明它较为有害。同理,M(z) > 0可以表示样本对训练相对有益,M(z) = 0可以表示样本对训练没什么用。
估计定义
对于第t个epoch的Moso值为在当前模型参数下,损失函数在去掉数据后的数据集和在数据上的梯度方向的一致性。通过正交的正负,可以做到与原始定义统一含义。同时通过缩放,达到同样的效果。最后,对所有的epoch计算的Moso值取期望,即为最终一个样本的Moso值。
实现细节
在实际计算中,在模型训练时会将w和η存好,使得总的时间复杂度为O(Tn)。具体算法如下:

源码实现:
1 | def MoSo_scoring_exact(net, dataloader, criterion, lr = None): |
误差分析
对实际值和估计值进行有偏估计,为梯度范数:
为减少误差的影响,不会将代理网络(surrogate network)训练到完全收敛,而是进行少量的epoch更新。
实验结果
剪枝前后数据集相关度
使用Spearman相关性分析(CIFAR-100样本分布不是正态分布),相关性为0.913,为强相关:
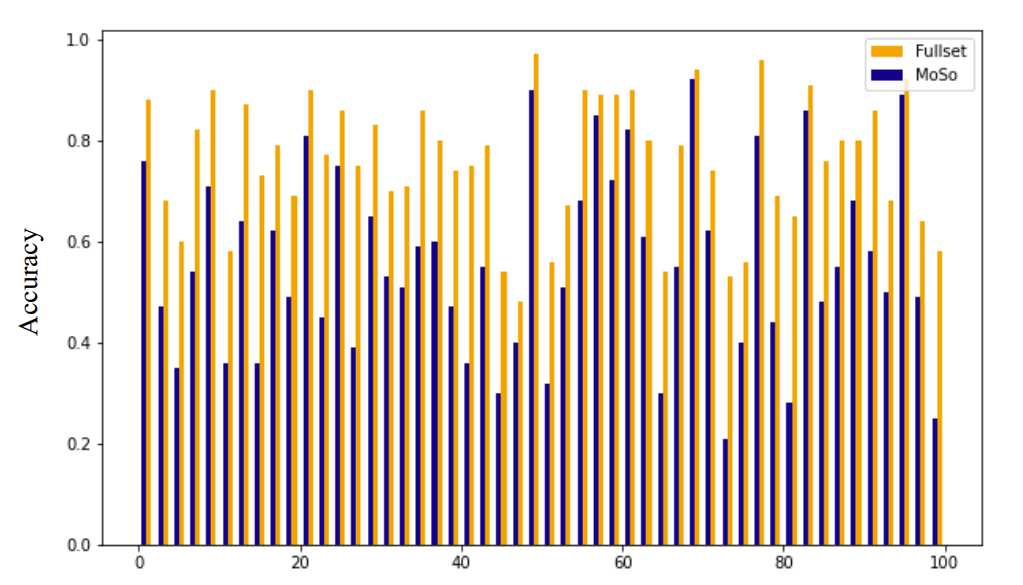
剪枝结果
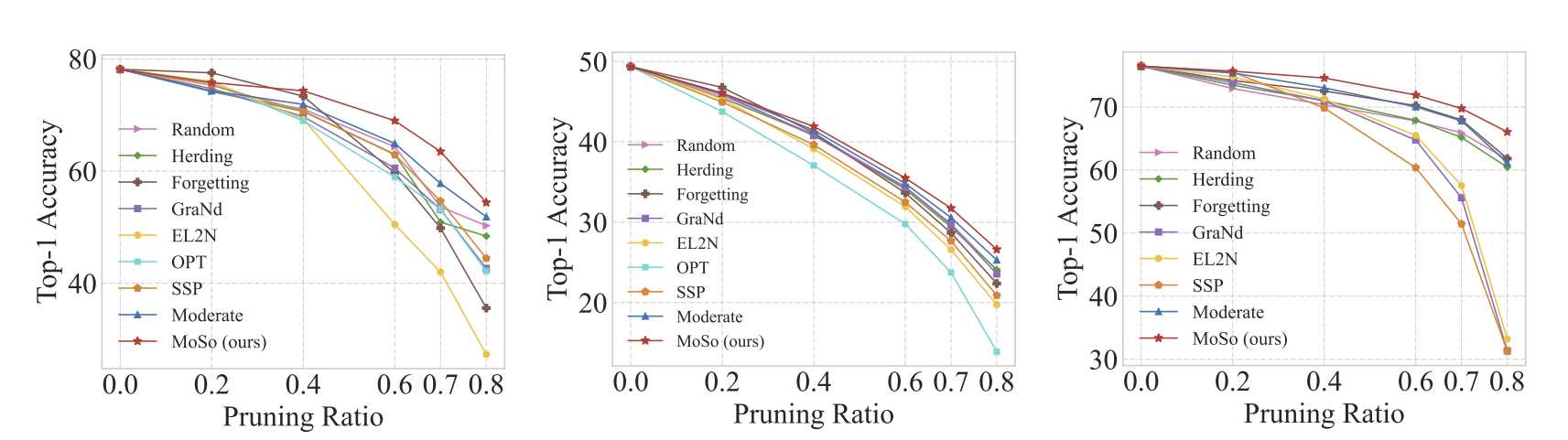
代理网络选择ResNet-50,训练50个epoch,batch size默认256,随机采10个epoch计算Moso.
消融实验结论
- 对训练动态的注意机制很重要,而且仅仅从收敛的代理网络中得到的梯度范数不足以衡量样本的重要性。
- 对于采样t的实验,证明t越小,方差越大,性能越差
- 并行计算增益:如果训练集很大,单个样本的影响可能会被掩盖,从而使其难以测量。然而,在一个相对较小的训练集中,单个样本的影响可以更灵敏地反映出来,也更容易被捕获。
- 不训练代理模型到收敛的影响:增益不大,但是时间消耗翻倍
其他发现
看完源码感觉好像应该有一篇叫做AOSP的文章作为铺垫,它好像在反映样本梯度与支持梯度之间的差异:
1 | def cal_AOSP(classifier, sup_grad, lr, data, device, criterion): |
D² PRUNING: Message Passing for Balancing Diversity & Difficulty
这是ICLR 2024的poster文章 Arxiv地址: https://arxiv.org/abs/2310.07931
图的建立
这篇文章考虑到样本之间具有一定的关联性,因此使用了图论的思想,比较形象,但还是一种比较static的方法,没有选择在训练中动态变化重要性指标(可能是计算资源限制)。先看图的初始化部分:
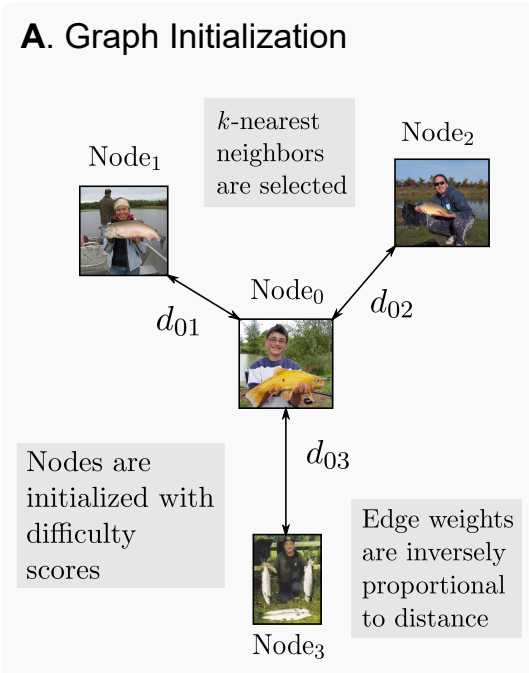
对于数据集中的每一个样本,这篇文章将其视作一个Node,然后针对每一个样本,可以得到它的embedding vector, 从而可以得到样本与样本嵌入空间内的欧拉距离.
由此,我们可以建立连通无向图。但对于数据集中没有太多相关性的样本(比如一只猫和一辆车、“abc"和"996”),这条邻边的建立意义几乎不存在。所以,文章选择前k个最短距离,由此可以建立一张图(不一定连通,但每一个节点必定有k个邻接点,但理论上构成应该是每一个类别的划分)。
对于每一个节点,它也有自身的意义,对于Dataset Pruning方向,样本最重要的意义在于对任务的贡献度,最直观的就是对分类任务的作用。在这个"意义"上面已经积累了许多"打分"的想法,比如GraNd和EL2N分别使用梯度和error向量作为打分依据、Forgetting使用在一个样本被正确学习后遗忘的次数、还有基于熵函数的方法、考虑Coreset在数据集上的覆盖的CCS方法、以及Moderate、AUM等等方法。这些方法都可以作为样本的特征值:
这里的f为任意一个评分算法。由此,对于任意一个数据集,都能建立一张图。
正向传播
对于一个样本和它的邻接点,仅仅连起来是没什么太大意义的,比如K张噪声极大的图片,这是需要在Coreset中大量删除的东西,而也有研究得出,太多了"有用"样本反而会在高剪枝率上表现较差,甚至不如随机,因此文章做了一个trade-off样本多样性和有效性的方法——正向传播和反向传播,我们先看看它的正向传播(正反传播的思想来自一篇2017年的文章):
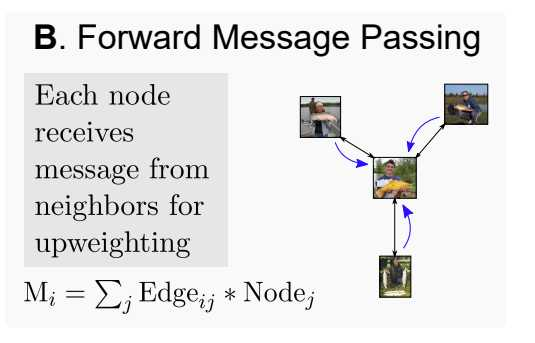
其中i为进行传播一个样本,j为与之相邻的节点,为实验前设置的超参数,用于缩放欧拉距离:
对于每一个节点,都会进行一次操作,因而我们可以认为:一个样本和它相邻的样本具有相近的重要性,可以由之中任意一个进行代表。在每一个样本进行一次正向传播后,我们将最终的特征值进行排序,然后进行修剪。
反向传播
Dataset Pruning的最终目标是为一个大数据集生成一个子集,使之满足计算资源和存储资源,并且尽可能少地损失性能,理想条件下达成优化性能。在这篇文章中,使用了一个反向传播,来降低选择一个"重要"样本后仍选择一个"重要"样本(即重复选择相似的样本导致多样性变少)的可能性。
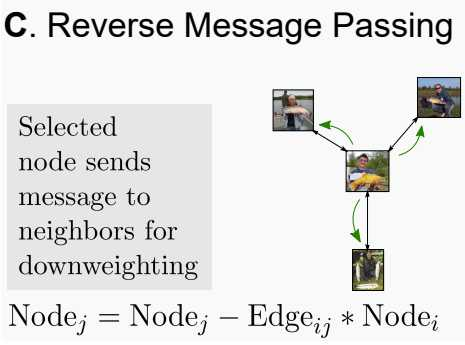
在将一个样本加入Coreset后,我们将它的特征值乘以embedding vector的欧拉距离,减给它的邻节点们,从而实现降低邻节点重要性。
实验结果
值得注意的是,这篇文章还探究了NLP数据集上的表现。具体实验数据结果可以查看原文。
Sieve: Multimodal Dataset Pruning Using Image Captioning Models
这是 CVPR 2024的文章 Arxiv链接:https://arxiv.org/abs/2310.02110
方法概述
这篇文章和其它CV方向的pruning方法有一些不同:它没有直接从图片对训练的效果角度切入,反而从图片的描述文字/标签入手(文中称为alt-text,就是html里面img无效后被替代的文字),先贴一张pipline:
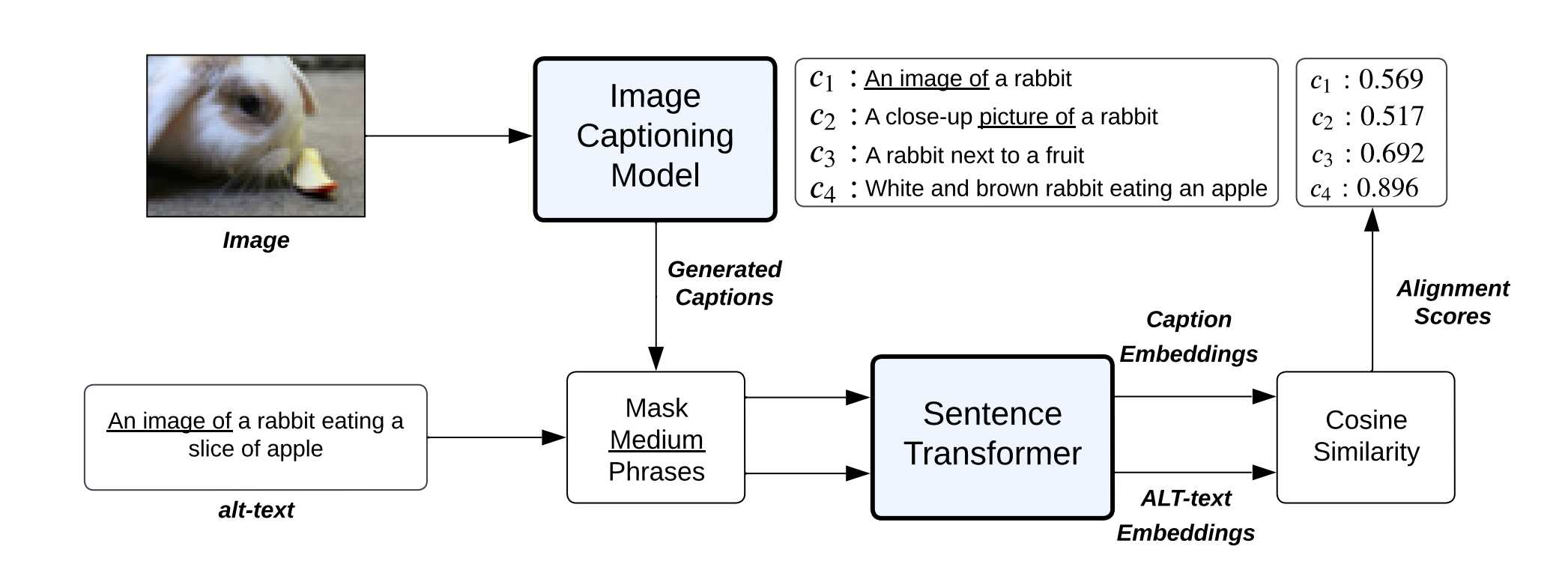
可以看到,这个方法的主要部分就是一个Image Captioning Model(通过图片起标题的预训练模型)、一个Mask Medium Phrases模块(这个很有趣,没有在label方向上做这个事情的)最后是一个生成embedding vector的模块。
核心组件
Image Captioning Model
这个是一个pre-trained的模型。训练集包括两大部分:一部分是网络上大量爬取的数据集(Conceptual Captions、Conceptual 12M、SBU captions等等)还有一部分是人工标注好的数据集(Visual Genome、COCO)。在标题生成上,文章选择Nucleus Sampling方法,这是一种解决2-8定律的方法(也是长尾定律,这在很多领域都有涉及),简单来说就是从头部的20%中采样——对给定概率阈值p,从解码词候选集中选择一个最小集,使得它们出现的概率和大于等于p。然后再对做一次re-scaling,本时间步仅从集合中解码。
至于生成模型的选择,文章选用的是BLIP,当然也能够选择GIT等等,这些作者做了消融实验,发现BLIP是较好的那一组。最后,通过图生文模型,生成了r个标题:
Mask Medium Phrases
这个模块做的工作很简单,也很有趣,就是把a picture of, an image of 等等图片相关的量词短语删掉,避免出现"a picture of a cat"和"a picture of a car"在embedding space中产生的向量具有相似度。这里直接附上它的余弦相似度更为直观:

Sentence Transformer
这个就是一个encoder,将去除定冠词的alt-text和标题映射到embedding space里面,用于求余弦相似度。最后以最大的余弦相似度(Sieve Score)作为其中一个修剪数据集的方法,在具体实验中,还将Sieve Score 和 Clip Score做了一个min-max当作一个指标。
实验结果
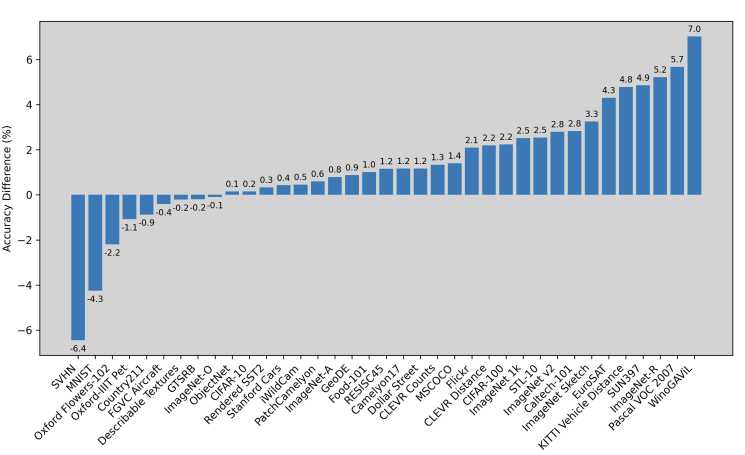
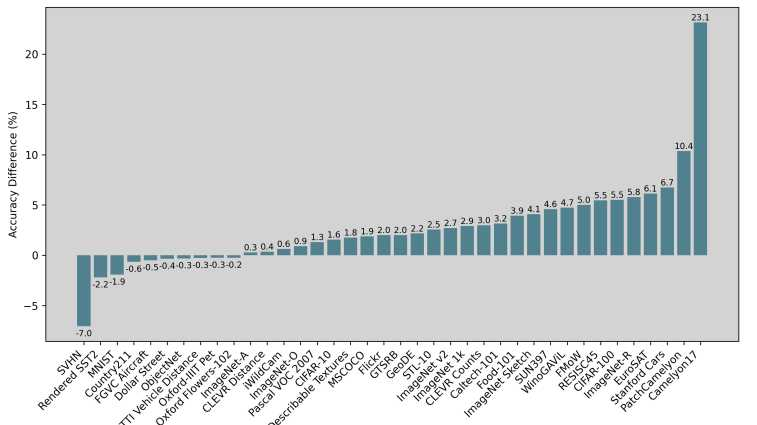
在38个分类和图文检索任务中,发现这个新指标所形成的子集具有更强的推理技能(左图为中等数据集128M,右侧为大数据集1.28B):